世界の材料科学者が論文中のグラフに残してきた、星の数ほどの実験データ。
それらを集めたオープンデータベースを作れば、材料科学の発展は加速できるはず。
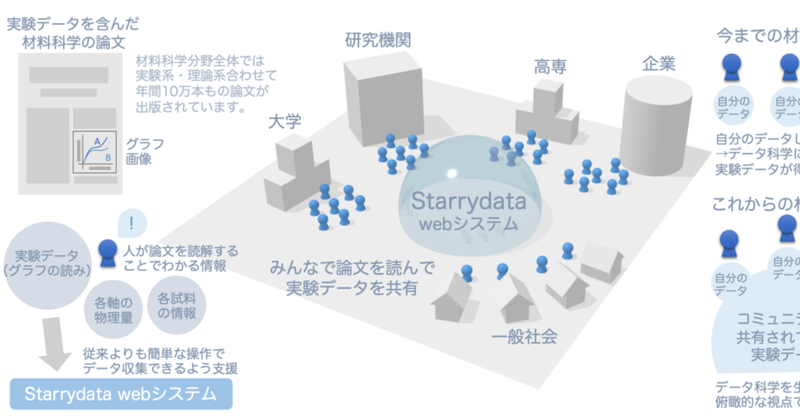
そんな思いで立ち上げたプロジェクトが、Starrydata(スタリーデータ)プロジェクトです。
Starrydataプロジェクトは、材料科学の論文中のグラフ画像から実験データを抽出することで、Materials Informatics (MI)研究に使う巨大なデータベースを作る研究プロジェクトです。Starrydataは単一の研究プロジェクトではなく、実験データMIという共通項を持った多数の研究プロジェクトの複合体です。各研究プロジェクトで論文から集めた実験データを1つの共通のデータベースに保存して、そのデータを他のユーザーも利用できることにすることで、誰でも使える巨大なオープンデータベースを作っています。
Starrydataプロジェクトでは2016年にStarrydata webシステムを開発しました。2017年にはその改良版としてStarrydata2 webシステムを開発し、正確で詳細な実験データを、専属データ収集者の手を借りて効率的に集められるようになりました。2023年には、Starrydata上のデータを検索・閲覧できるStarrydata Explorerもリリースしました。これらのシステムは、私たちの論文を引用することで、営利・非営利を問わず無償で利用することができます。
草の根の共同研究で始まったStarrydataプロジェクトへの協力者は少しずつ増え、2017年には理化学研究所 革新知能統合研究センター(理研AIP)の支援を受けたデータ収集も始まりました。また、国内の大手材料メーカーや大手自動車メーカーらとの共同研究、JST-CRESTや科研費などの競争的研究費による研究も行ってきました。桂は2020年11月にNIMSへと所属を移し、現在は計11名の専属研究チームでStarrydataの研究に取り組んでいます。
Starrydataは、世界最大の熱電材料の実験データのデータベースとして最先端の研究に活用されています。そして磁石材料、圧電材料、準結晶関連物質、低/高熱伝導率材料、固体物性科学、電池材料などの材料物性データの収集も行っています。将来的には、材料科学全体の実験データをデジタル化した巨大なデータベースとして、世界の実験値MI研究の基盤になることを目指しています。
材料科学にはさまざまな研究分野があり、各分野の論文には典型的な実験データのグラフがあります。Starrydataのデータ収集対象はそのようなグラフです。熱電材料だったら熱電特性(ゼーベック係数、電気抵抗率、熱伝導率、無次元性能指数ZTなど)の温度依存性、磁石材料だったら磁化ヒステリシス曲線などです。このようなグラフに集中してデータ収集を行うことで、データ収集手順を統一して効率的にデータ数を増やしています。
Starrydataでは他の材料物性データベースと異なり、テキストやグラフの中から1データ点を選ぶのではなく、グラフの曲線を丸ごと収集することで情報量を増やしています。また論文や試料の選別を省略し、掲載されている試料を片っ端から収集対象にしています。これによりデータ選別の負担を軽減するとともに、データの恣意的なバイアスを減らし、データからさまざまな情報を引き出しやすくしています。
このような論文データ収集は、論文の著作権の侵害にはならないことを確認済みです。著作権は創作物にかかるものなので、論文のレイアウトや本文の文章、グラフのデザインなどは著作物です。しかしグラフ画像中に示されている数値データは、客観的な事実です。このような数値データを集めてデータベースとして共有することに問題はないですし、各データの元論文も引用しております。
Starrydataでは人の手でグラフからデータを集めています。論文中の対象グラフのスクリーンショットを撮って、独自開発のStarryDigitizerにペーストします。そして横軸・縦軸の物理量と単位、両端の目盛線の位置と読みを入力します。続いて、グラフに載っている試料について、各データ点の位置を検出またはクリックすることで、もとの実験データを取り出します。複数のグラフに同じ試料が載っている場合は、それらを同じ試料として扱います。
AIの発展した現代でも、論文から情報を集めるには人の読解力が必要です。論文の書き方は個人差が大きいため、目的の情報を抜き出せるプログラムを作るのは困難です。専門知識に基づいて著者の意図を推測する必要があります。試料の対応関係を読み取り、化学組成や製法を記録する必要があります。計算データや引用文献のデータ、同じグラフ上にある別の物理量のデータなどを除く必要もあります。記号が示す物理量や、凡例の意味、グラフ中の矢印や×10nなどの係数の意味、軸の切れ目や複数軸の意図を汲み取る必要があります。著者由来のミスも意外と多いので、おかしいと思ったデータを元論文を辿って再検証する必要もあります。これらの臨機応変な作業は、人が行ったほうが遥かに効率的です。そしてそこから得られる論文データ収集の膨大な知見が、同じ作業を行う自動プログラムの開発にもつながると期待できます。
一方で、人が行うと面倒で間違いやすいけれど、自動プログラムなら速く簡単にできる作業もあります。著者名や論文タイトルなどの書誌情報の入力や、データ点の検出、単位変換、大量データの整理とグラフ化などです。そこでStarrydataでは、データ収集者がDOIのリストを入力しただけで、論文の書誌情報を自動取得して、出版社の元論文へのリンクやデータ入力ページなどを自動生成できる仕組みを搭載しています。独自のデータ点検出アプリでは、色や点の大きさに基づくグラフトレースができます。データの単位は、登録時に接頭詞なしのSI単位系に変換されるため、同じ物理量のデータは全て同じ単位で表示されます。GPTなどの外部AIを用いて、試料情報の入力作業を簡単にする仕組みの搭載も進めています。
そんな風に、データ収集者と自動プログラムが相互補完することで、論文からの実験データ収集という難しいタスクを実現したのがStarrydata2 webシステムです。下のバナーをクリックするとStarrydata2 webシステムに移動しますので、右上の「Sign up」を選んでアカウントを作ってください。そしてログインすると、データベース内のデータにアクセスしたり、自分で新しいデータを論文から収集・追加できるようになります。
このプロジェクトの目的は、世界の材料科学の加速です。材料科学の研究者は、どこか「成果が出ないのは当たり前だ」と思って研究をしているように感じます。材料科学の歴史を変える材料を発見できたらいいけど、それは難しいので、とりあえず形だけでも成果が出ているように見せるという考えになっている方も多くいるのではないかと思います。
でも材料科学の研究の進め方を変えれば、その状況を変えられるかもしれません。まず、過去の研究者がどんな実験をしてどんな結果を得てきたのかを見ること。次に、まだ十分に実験されていない材料のリストから、データ科学などのいろいろな俯瞰技術で有望な候補材料を見つけ出すこと。そしてそれらの実験結果を、論文やデータベースとして後に続く研究者に共有すること。その最初のステップとして、すでに出版されている論文のデータをデジタルアクセスできるようにしようと考えました。
過去の実験データを集めて、機械学習などデータ科学によって解析すれば、研究の効率が高まる可能性があります。過去に行われたのと同じ実験を繰り返す、時間と費用の無駄遣いがなくなれば、科学の発展に少しでも役立てるはずです。
ただ、この作業量は膨大です。このため私たちのチームに全てのデータ収集を任せるのではなく、各ユーザーが「足りない」と思ったデータを自発的に追加してくれるようになることが理想的です。私たちがデータ収集のための入れ物を提供し、研究者が論文を読むたびに習慣として掲載された実験データを登録していくという習慣が材料研究の世界に根付けば、論文に掲載されたデータはすべてStarrydataに掲載されていて、誰もが自由に自分の研究に使えるようになると期待できます。

論文から抜き出したのは、元のグラフ画像そのものではなく、そこから読み取った数値データです。従って、著作権をまったく侵害せずデータをシェアでき、研究に自由に活用できます。
「Starrydata2 webシステム」では、機械学習などのデータ科学研究における、使いやすさを想定したデータ出力機能を備えています。
Starrydataの全データは、まとめて無料でダウンロードできます。ダウンロードできるデータ形式は、Excelなどで読み込める表形式の生データ(CSV/JSON)と、それらを補間したグリッド状のデータファイルです。APIを使っての自動データ取得も可能です。
Starrydataでは、登録データの種類に制限は設けていませんが、専属のデータ収集者をつけて、分野を決めてまとまった論文データ収集を行うこともあります。
その分野のひとつが、熱電材料です。過去4年間で7000本以上の論文を読み込み、4万個以上の試料の熱電特性データを集めました。このほかにも、磁石材料や準結晶など、共同研究者らの希望に応じて、ここまで7分野のデータ収集に取り組んできました。
この分野は、これからも新しく増やしていく予定です。ゆくゆくは、材料科学全体をカバーしたデータベースにすることを目指しています。現時点で収集されているのは、熱電材料、磁性材料、低熱伝導材料、凝集体、高熱伝導材料、ハイパーマテリアル、圧電材料の7種類です。
Starrydataシステムは、東京大学在籍時に桂ゆかりが発案し、熊谷将也がプログラムを開発しました。このシステムは、私たちのアカデミックな研究の一環として非営利で運営されています。そのため登録されているデータ利用に費用はかかりません。
ただ一点、Starrydata2を使って研究を行った場合は、以下の論文を引用してくださるようお願いします。論文の引用回数増が、私たちの業績評価につながります。
Y. Katsura, M. Kumagai, T. Kodani, M. Kaneshige, Y. Ando, S. Gunji, Y. Imai, H. Ouchi, K. Tobita, K. Kimura, K. Tsuda, Data-driven analysis of electron relaxation times in PbTe-type thermoelectric materials, Science and Technology of Advanced Materials (STAM) 20 (2019) 511-520.

現在、プロジェクトにおけるデータ収集作業は、私たちの研究費でデータ収集者を雇用して行っています。同時にクラウドソーシングにより、論文1本あたりの報酬を定めた形でも進めています。
データは増えれば増えるほど、使いやすさが高まります。このサイトにアクセスしてくれた研究者の皆さんには、ぜひご自身の研究データをサイト登録してもらえるようお願いします。
また研究者の方々には、できれば研究費の一部を使い研究業務員を雇用するやり方でのデータ収集も検討いただけるようお願いします。
一方で企業の皆様には、寄付金による論文データ収集代行をご検討ください。寄付金により我々が研究業務員を雇用し、データ収集を行います。収集データはすべて公開されるため独占利用はできなくなりますが、他社に先駆けて大規模実験データを活用した研究を行えるようになります。
Starrydataにより、一人でも多くの研究者が一つでも多くのデータを活用し、科学の発展に貢献できれば何より幸甚です。

論文実験データ収集プロジェクト「Starrydata(スタリーデータ)」は、2015年7月に始まりました。
熱電材料データベースの作成から出発して、材料科学の実験データが登録された「Starrydata2 Webシステム」が完成、日々多くのデータが追加されるようになりました。
私たちは、様々な形態で研究を進めていく仲間を受け入れています。
民間機関、企業等との共同研究、委託を受けた研究など様々な形での研究が可能です。まずは、ご連絡ください。